
熊中哲 /沃趣科技联合创始人
嘉宾介绍:曾就职于阿里巴巴和百度,专注于关系型数据库Oracle/MySQL,对关系型数据库的核心技术、架构、存储技术、运维自动化、云计算都有一定的研究。在阿里巴巴 B2B 期间开启了数据库运维自动化工作,设计研发了基于Oracle的高可用软件,广泛使用在生产环境,之后参与阿里云RDS的开发工作。2012年,作为联合创世人,创办沃趣科技,目前负责产品和研发工作,公司于2016年挂牌新三板,产品多应用于证券,保险类金融客户。
讲师:熊中哲
校对:小百科
想看精彩 Q & A,直接拉到最底部。

今天很荣幸来到这里,其实关系型的数据库很早出现在这种场合,但是对我们来讲,所有的特质都非常实用。看到 Kubernetes logo,我第一个想到船舵,第二个想到了大海。Kubernetes对我的影响,正如我已看过了大海,所以我不能假装没有见过。

什么是 RDS
说到 RDS 对我们来说很简单,都是数据库的背景,问题是 RDS 做在什么上面。
这是 IDC 的图。2015 到 2020 年对于传统的 IT 架构,公有云和私有云的市场分配。
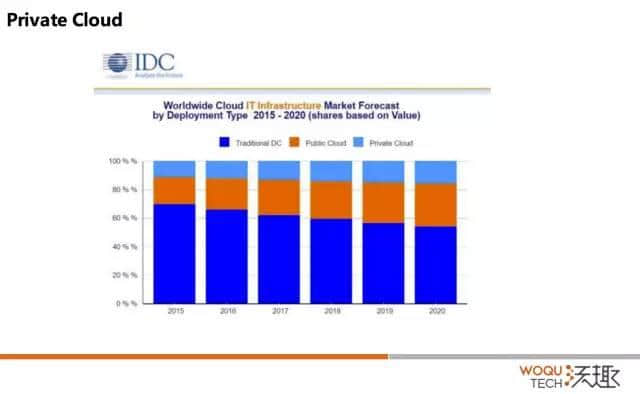
大家可以看到最上面是 Private Cloud,中间的是 Public Cloud,最下面是 Traditional IT 的架构,对于我们来讲,找到这个问题的答案很简单。从国外来讲,亚马逊已经做得非常好,国内大家也可以看到,事实上也已经出来了,就是我原来工作的那家公司。
对我们来讲,我们的发力应该在 Private Cloud上面,我们做它不敢说优势,但是没有明显的劣势。没有明显的劣势,就是看到国内没有专门做数据库的公司投入到 RDS 里面去,绝大多数公司投入在 IaaS 和 SaaS 这一块。
RDS,RD 就是关系型数据库,那么到底从哪来切入呢?从我自己来讲,我一直做 Oracle、MySQL,从毕业一直到现在做了十年,但是我不能凭我的爱好做选择。
我拿到一个图,截止到 2017 年 7 月份,这里面有 Oracle、MySQL,有很多数据库。大家可以看到, Oracle、MySQL 一直名列前茅。看到这组数据我非常开心。那么,今天咱们的话题就从 Oracle、MySQL 来切入。

Service:AWS RDS

我拿了亚马逊 RDS 来举个例子。当然,这并不代表全部。它列举了一些功能,当然也不仅限于列举的这些:数据库的安装、部署、打补丁、备份功能。
在这个基础上,它希望平台是高性价比的, 同时它希望交付的服务是 Fast performance,不是 high performance,等会我会解释为什么不是 high;同时兼备高可用和安全性。
如何构建 RDS
我结合这几点我讲一下,我们是如何构建 RDS。

说到性能,关于数据库导致的问题也很多。我应用的架构设计,从上面到下面,真正落到数据库还有很多站。还有可能数据库本身设计的问题、执行计划的问题、CPU 的内存、GPU,有种种问题。从我们做数据库来讲,我经常说我们有三板斧,我想每个行业都有自己的三板斧。
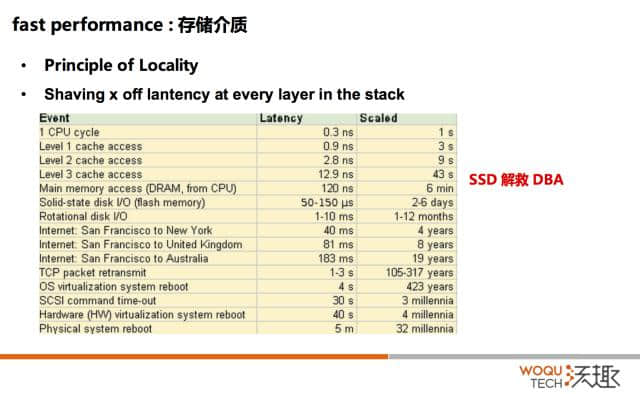
我们去看一下对 IO 要求最高的关系型数据库。我们认为数据持久化最关键在于,如果 online redo log 的落盘,那么我认为数据保存了。但是看一下 redo log IO 特性,同步的、连续,512 字节的。
这些东西反映到对存储的要求是什么?IOPS 延时。要求是什么呢?常听到人说 IOPS 越高越好,延时越低越好,这句话是对的。但是往后面要展开的是,是我们要关注 IOPS 以及延时的质量。

我们拿到数据,不管是测 SSD、flash 卡,或者拿到一个数据库的时候,它说我的 TPS 能够到 20 万,我的 IOPS 能够到 10 万,我的延时是 67 微秒。那么你可能需要问一下达到 10 万 IOPS 和所谓的延时 67 微秒是同时发生的吗?这个 67 微秒是平均值吗?我怎么能够知道你 10 万 IOPS 里面,99.99% 的延时落在哪个区间的?写过代码的,大家都喜欢用火焰图去做操作。其实我们有时候要画一些直方图或者火焰图看一下,大多数的延时落在哪个区间。这个时候配合均方差来看一下抖动。
SSD
我第一次接触 SSD 是什么时候呢?我记得应该是 2009 年下半年,而且直接就是生产环境,我记得我当时拿到了华为的 SSD。 在阿里巴巴,我们是互联网公司,我不知道是不是最早,但是应该是比较早的,在生产环境核心系统用的 SSD。我们当时同事大家一起商量,SSD 出来我们 DBA 回家了,就不用干活了。但其实还是会有很多问题的,非常多的问题。
现在的 SSD 和 Flash 主要是基于 NAND 存储颗粒做的,它有一个写放大和垃圾回收的机制,这里不展开了,线下可以讨论。它对 IO 有哪些影响呢?
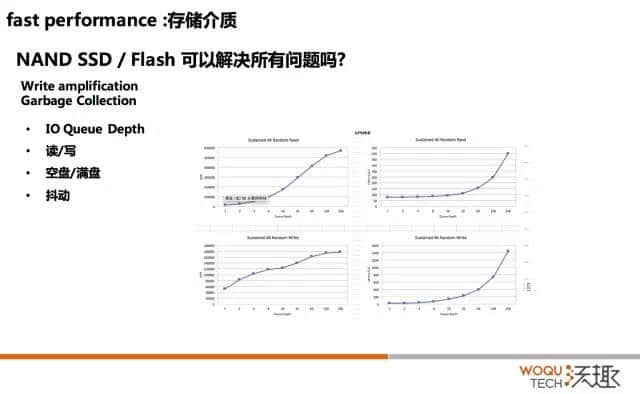
这个图是在 4K 的情况下做一个随机读和随机写。随机读是时候,IOPS 可以到 60 万,随机写的是 IOPS 是 18 万,大家可以看到读和写差距非常大。第二个是队列深度,Y 轴是 IOPS 数值,X 轴队列深度。IOPS 在 256 队列深度的情况下,才能测到最大值。
假如咱们有个厂商说:“我能够到 60 万的 IOPS。”但是可能应用程序用不了,因为应用程序制造不了这么深的队列。所以当我们换上 SSD、Flash,性能没有提升,你可能要看一下应用的 IO 模型是什么样子。
还有抖动,我们看一下上面。大家可以看到,我们写的时候,256 的队列,我们 IOPS 最高,18 万的 IOPS。但是我们延时已经到了 1.6 毫秒,这只是物理层面。大家知道一层一层放大,有的是指数级放大。所以这个 1.6 毫秒,可能放大到数据库那边,可能就是 6 毫秒。6 毫秒是不能接受的,6 毫秒就是大家经常说的慢。慢是一个很逻辑的概念,但是放到数据库里面超过 3 毫秒你就会感觉到慢。
这里可以讲一下,现在再拿到 SSD 会不一样,因为没有预留空间,现在都会有预留。可以给大家两个值,如果买的消费级,会预留 8% 的空间,如果买的是 NVMe 或者 SAS 的会预留 50% 的空间,就是你拿到一块盘 1T,实际的容量是 1.5T,所以贵也是有贵的道理的。
IO 测试模型
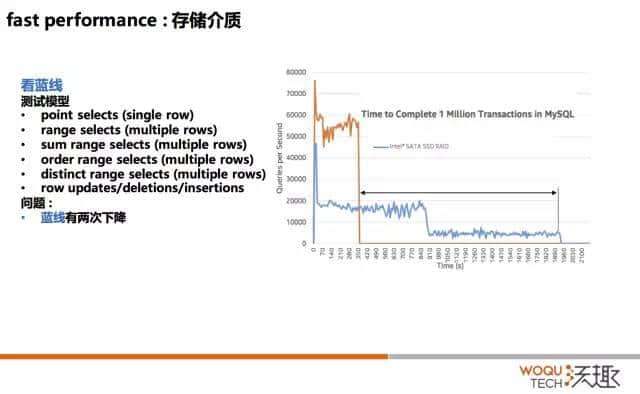
这是一个 IO 测试的模型,我们看蓝色的线。这个模型是什么呢?就是随着时间的移动,什么时候能完成 100 万的 TPS。它的模型首先是单块的,基于 PK 的查询或者 UK 的查询,基于范围的查询,后面是增删改查。大家可以看到这里有一个刚才讲到的,当从读切到写的时候,性能的损耗大家可以看到像断崖式的,这是从数据库来讲非常大。
适配存储
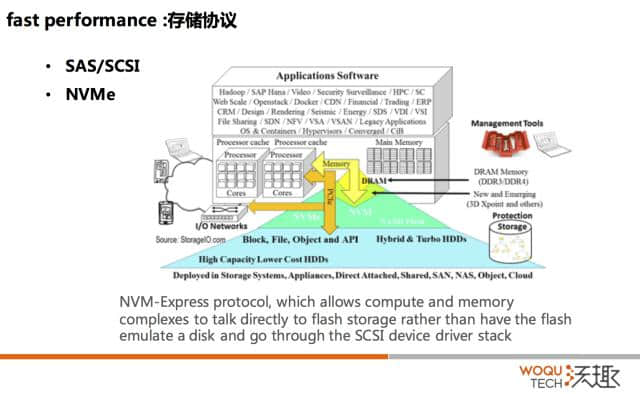
我们已经用到了最好的存储颗粒,所有的问题都解决了吗?因为原来高端的,我们有接触了一系列的存储,高端的都是机遇 SAS 或者 SCSI 协议的,原来是机械卡,基于盘片转动然后寻道。寻址的开销很大,但是协议的开销相对来说就不大了。但是一旦用到这么快速的固态颗粒,这个时候 SCSI 协议的开销就太大了。
所以协议层要去适配快速存储。有了 NVMe 比原来的 SAS,它的数量比原来多很多,最后的结果就是非常快。
从用户角度来讲,你得到的好处是什么呢?NVMe 确定了一个标准,原来大家要去用这些东西你要装驱动的。为什么?因为在 SSD 和 Flash 这块有些标准是不统一的,不统一就要装驱动。但是有了 NVMe,标准统一,驱动都 build-in 到内核,你未来用它就像用硬盘一样的,你用硬盘装过驱动吗?肯定没装过,因为操作系统已经装了,现在 NVMe 也是,NVMe 的盘插进去就能用了。
而且它还有一个很好的特性,支持热插拔。有了这个之后,大家觉得 DBA 的工作就完了,你用了一台机器装了 SSD,然后 OK 了。
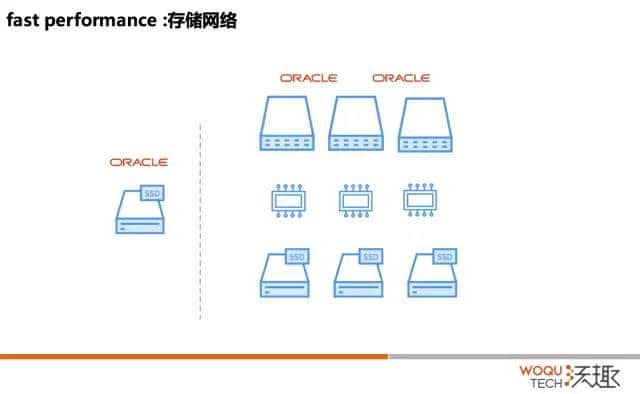
但我们今天讲的是 RDS,其实不讲 RDS 的话,这套架构也没人用了吧。这种架构不时髦了,我们现在标准的用法是什么呢?就是需要保证计算节点的扩展性和存储的扩展性要分层。我要分层,专门的存储节点,专门的计算节点,存储节点到看盘。然后就可以水平扩展,跟的计算节点解耦了。
InfiniBand:连接存储网络
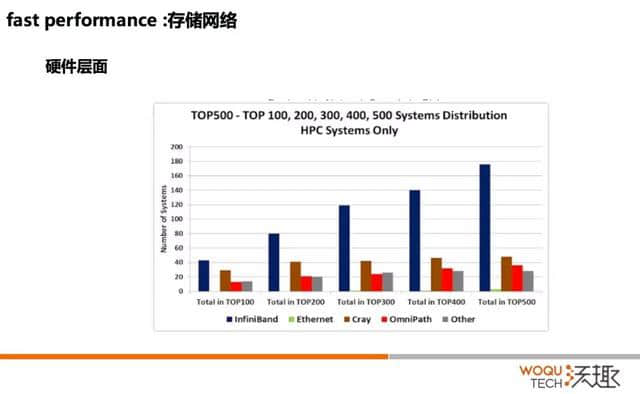
但是这两个之间,总得通过网络连起来吧,那这就是我的存储网络,存储网络就是我得用什么把它连起来呢?
那就是 InfiniBand,InfiniBand 原来是用在超算里面的,有的同学在研究生阶段应该早就接触过 InfiniBand。全球前 500 个 HPC 的系统中,使用 InfiniBand 系统的接近 180 个,遥遥领先。
说两个名字,我们的太湖光和天河二号,就是在这个排名,而且是排名第一第二。而且我们的太湖之光和天河二号用的就是 InfiniBand 技术,但做了一些修改。
为什么用 InfiniBand 呢?它有几个特性,一个就是延迟非常低。它的端口到端口是百纳秒级,还有一个它的带宽非常高。大家可以看一下以太,我们直接看最流行的原来都用 FC,大家用 EMC 的。最习惯的就是你的主机装一个 HBA 卡,然后基于 FC 去联后端的存储。那 FC 的协议大家可以 8GB、16BG、32GB,但是 InfiniBand 到了 200GB。InfiniBand 到了 200GB 的产品已经发布了,但是说实话没有人会用。除非对超算领域要求极高,不然 56GB 和 40GB 绰绰有余。
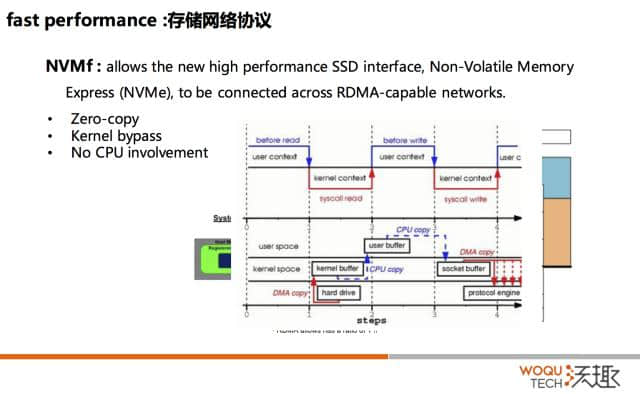
Zero-copy、Kernel bypass
现在计算/存储分层了,存储节点有了,快的介质,操作协议也很快,网络也很快,工作完了吗?还没有完。
那我们需要一个什么样的东西呢?大家可以看一下,就说如果我是一个存储节点,要把我的数据传输出去。大家可以看下这是一个标准的操作。首先要基于的 DMA,这个时候你的 CPU 是不用参与的,拷贝到 kernel 的 buffer。接下来,你的 CPU 参与了,要拷到 user buffer,这个时候寻址空间是不一样的,而且 CPU 要切换。用户的程序经过计算,拷贝到 socket buffer,也就是 kernel buffer。然后 CPU 又要切到 kernel mode,再拷到 socket buffer 来,完了之后再通过网卡再发出去。
大家看一下操作慢在那里。第一,份数据反复被拷贝;第二个,你的CPU切换了两次,这都是巨大的开销。
所以如果我们能够做到 zero-copy、Kernel bypass 这种切换去掉,然后整个过程当中, CPU 不用参与,所有的开销就都可以省掉,最后的结果就是假设你有的场景从你的存储阶段输入到计算节点的话,你的存储节点只需要开辟一段内存。用户的程序和你本身传输它的 HCA 卡,不需要通过 CPU 的切换,就能够去访问它。然后通过队列发出去,而且这个队列里面不是数据,只是一个 Entry 指向内存的一个指针而已,整个世界变得完美了。编程复杂吗,也没有那么复杂,基于 OFED 编程和 socket 没有多大区别。
其实基于这个来讲,大家可以看到它做了一些什么事情?原来这些事情是 CPU 参与的,现在相当于 offload 到支持 RDMA 的 HCA 卡去了。就像现在做一些 AI,就是把一些基于某一种场景的计算,从一个通用的 CPU 到一个专用的 GPU 里面去,这个也一样。
对你的好处有两个非常明显的,除了延时非常低以外,你的 CPU 可以做更多的事情,结合某一个场景,因为这个场景不合适,所以数据我说一下。CPU 参与的过程当中,你的 CPU 的开销要降低 76%。还有你的内存,我内存不是要拷来拷去嘛,对于内存来讲也一个负载。大家可以看到,RDMA 始终和你传输的数据是一样的,但是如果你用socket的话,在发送的时候接近 4.5 倍,在接受的时候也超过 4 倍,这是对主存的开销。
完善的 FA 机制
所有的事情完了,那跟 RDS 有什么关系呢?就是我们一旦用到这个场景,所以我们用到存储专有的技术。它带来的问题是什么呢?很多用不了。
我们要支持更多的数据库,我们在存储端要做一些牺牲,我们要追求完善的机制,这就是相对的,这个性能本身也很高,但是我们要相对做一些牺牲,我们要从专有的整个存储领域走向一个更开放的,然后其他数据能用的,但是可能性能会有一点点损耗的产品。
Services
接下来,我们讲一下 Services,讲到 Services 可以展开一下。高可用是一个非常重要的点,没有高可用谈其他的没有什么意义。其实 Oracle RAC 和 MySQL Galera 有非常多的工作可以做,但是我们不能拿着锤子看到所有东西都是钉子。
用户要的是什么呢?其实就是故障检测的一个机制,免干预切换流程 60 秒,可能是 45 秒,可能是 90 秒,这要根据用户的业务来调整。但是我们要做到在 X 秒内完成一个切换,并且对应用来讲是透明的。“透明”的意思是可以报错,但是过了这一段时间之后,你的应用不需要做任何事情又恢复了。
Kubernetes 与 RDS
我们用做了一些什么事情呢?本身 Kubernetes 有 third party resource,还有可以写 Storage Plugin。基于这两个 object,我们写 RDS 的逻辑。
先说我们的主库,主库可以自动去切换,我可以通过 petset、statefullset 去做。我可以去挂备库,备库一样。但是有一个好处是什么呢?我在这里可以用它自己 endpoint service。Master 不管怎么切,我始终用 DNS,对我来讲没有任何关系,我也可以自动切换。
但我还有一种场景叫什么呢?就是我有一堆好的机器,我有一堆中档的机器,我还有一堆差的机器,它说你帮我分一分,那我基于 node 去做相关的东西。差的机器去做备份,包括逻辑的备份,物理的备份,但是有的时候物理的备份,我得跟主库跑在一起。这个时候我一样可以基于 Pod 的亲源性,把它调度到某个 node 上面来,这其实就是我们切合它的 TTR,以及 Controller 外部的动态存储分配,我们就可以做所有的工作了。
我们再结合一系列 Controller,还有安全。安全就是如果用开源的数据库,不管从日志层面,从数据层面,都可以拿到你的数据。你可以加密,但是现在的做法一般是把加密的密钥和数据文件放在一台机器上面。这就相当于保险箱和钥匙在一起,数据极易泄露。
之前类似于亚马逊,做一个 KMS,把这些密钥保护起来。这里我们也完全可以通过 Kubernetes 的 secrets 来实现。
我刚才讲的所有场景在内部已经在内部全部验证通过,只是在性能上有小小的问题,那么细节可以再线下讨论。
Q & A
Q1:RDS 是自己用,还是也给别人提供这个服务呢,给别人搭这个环境呢?
A:我们为什么需要 K8S 呢?我们在上面构建自己的业务,我们开发的成本会很低。第二我们的很多用户,要去使用 RDS,基本是早一批的 IaaS 的使用者,可能是 Openstack、VMWare、Zstack,适配是不能回避的问题,我们为什么不用一个事实的 PaaS 标准来做呢?
对我们来讲网络这块是适配的,而且存储没有刚才讲的那么复杂。因为数据库没有人想部署几千台,就像我之前在百度的时候,线上数据 1500 个左右。这个问题挺好的,刚好回答了我想讲的。
Q2:我想了解分布式存储在数据安全方面,有哪些冗余模式?
A:冗余模式对我们来讲一般是 mirror,三副本,或者基于纠删。不过还是看是拿 cpu 换空间,还是用空间换 cpu,那个资源更稀缺。
不过因为 cpu 的部分计算 offload 到 hca 卡上,加上现在 cpu 的计算能力非常强,拿 cpu 换空间,确实值得考虑,例如压缩,去重。
Q3:有没有读写分离的功能?
A:我们这一版没有规划,对我们来讲读写分离、或者分库分表从来不是一个技术问题,是业务问题。例如,update + select,这个 select 到底是到从库还是主库,是跟业务相关的。而且有的用户,很难找到分区键,或者改造成本极高。
还有一点,基于现在的存储能力,几个 TB 的数据,完全不用分库分表.