很多人对于华为海思芯片非常感兴趣,相关的讨论争论自然也不会少,在论坛上有时候也会看到。有人把它吹上天,也有人说它毫无技术含量。我看完之后痛心疾首,觉得很多人说的很多方面都是不对的。所以献上此文,客观介绍一下芯片的设计制造流程。
卖弄前先自我介绍顺便声明一下,本人海思新员工,但不从事芯片设计类岗位,只是最近听过一个关于芯片的培训,再加上本人对芯片如何实现等问题也比较好奇,所以搜集过一些非官方、不科学资料,发表一下浅鄙之见。
一、工艺制程并不是越小越好
OK,废话不多说,对于芯片,先说一些自己感兴趣的,可能涉及海思的不多。经常能听到有人争论40nm工艺、28nm工艺,14nm工艺,那么这个多少nm指得是什么呢?
它指的是mos管在硅片上的大小,mos管就是晶体管,它是组成芯片的最小单位,一个与非门需要4个mos管组成,一般一个ARM四核芯片上有5亿个左右的mos管。世界上第一台计算机用个是真空管,效果和mos管一样,但是真空管的大小有两个拇指大,而现在最先进工艺蚀刻的mos管只有7nm大。
说到这里,大家一定和我一样,非常好奇如何在一个15mm*15mm的正方形硅片上制作出5亿个大小仅为40nm的mos管。如果要用机械的方法完成这一过程,世界上很难有这么精密的仪器,可以雕刻出nm级的mos管,就算有,要雕刻出5亿个,所需要的成本、时间也是难以估计的。
借助光可以在硅片上蚀刻下痕迹,掩膜就可以控制硅片上哪些部分会被蚀刻。掩膜覆盖的地方,光照不到,硅片不会被蚀刻。硅片被蚀刻后,再涂上氧化层和金属层,再蚀刻,反复多次,硅片就制造好了。一般来说,制作硅片需要蚀刻十几次,每次用的工艺、掩膜都不一样。几次蚀刻之间,蚀刻的位置可能会有偏差,如果偏差过大,出来的芯片就不能用了,偏差需要控制在几个nm以内才能保证良品率,所以说制作硅片用的技术是人类目前发明的最精密的技术。
芯片可以靠掩膜蚀刻,批量生产,但是掩膜必须用更高精度的机器慢慢加工制作,成本非常高,一块掩膜造价十万美元。制造一颗芯片需要十几块不同的掩膜,所以芯片制造初期投入非常大,动辄几百万美元。芯片试生产过程,叫做流片,流片也需要掩膜,投入很大,流片之前,谁都不知道芯片设计是否成功,有可能流片多次不成功。所以国内能做高端芯片的公司真没几家,光是掩膜成本就没几个公司支付得起。
芯片量产后,成本相对来说就比较低了,好的掩膜非常大,直径30厘米,可以同时生产上百块芯片。芯片如果出货量很大,利润还是非常高的,像英特尔的芯片,卖1000多一块,可能平均制造成本100不到。但如果出货量很少,那芯片平均制造成本就高得吓人,几百万美元打水漂是很正常的。
海思芯片价格有没有竞争力,还得看华为手机出货量大不大。看到有人问20nm好还是40nm好,从大小上来看显而易见20nm好。20nm意味着mos管大小只有40nm的1/4。mos管工作时是一个充电放电的过程,mos管越小,它充电需要的电量越小,所以功耗越小。而且mos管小之后,门电路密度就大,同样大小芯片能放的mos管数就越多,性能空间越大。40nm工艺门电路密度是65nm的2.35倍。但以上都是在不考虑漏电和二级效应的情况下的理论数据。
当然,IC尺寸缩小也有其物理限制,当我们将晶体管缩小到 20 奈米左右时,就会遇到量子物理中的问题,让晶体管有漏电的现象,抵销缩小 L
时获得的效益。作为改善方式,就是导入 FinFET(Tri-Gate)这个概念,如下图。在 Intel
以前所做的解释中,可以知道藉由导入这个技术,能减少因物理现象所导致的漏电现象。
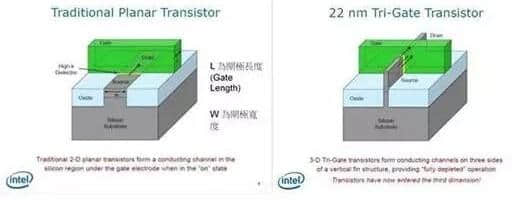
图1
为什么会有人会说各大厂进入10奈米制程将面临相当严峻的挑战,主因是 1 颗原子的大小大约为 0.1 奈米,在10奈米的情况下,一条线只有不到100
颗原子,在制作上相当困难,而且只要有一个原子的缺陷,像是在制作过程中有原子掉出或是有杂质,就会产生不知名的现象,影响产品的良率。
如果无法想象这个难度,可以做个小实验。在桌上用 100 个小珠子排成一个 10×10的正方形,并且剪裁一张纸盖在珠子上,接着用小刷子把旁边的的珠子刷掉,最后使他形成一个 10×5的长方形。这样就可以知道各大厂所面临到的困境,以及达成这个目标究竟是多么艰巨。
再说说二级效应吧,学过初中物理的都知道一个最简单电路的组成,包括电源、导线、电阻。接通电源,电流就瞬间流过电阻。如果把电阻换成电感,则电感会有一个逐渐充电的过程,这种情况下,电流就不是瞬间流过电感。
其实电阻也有感抗,只是非常微小,可以忽略不计。但如果接在电阻上的电压非常微小,电流量非常微小,那此时,感抗就不能被忽略不计了。二级效应在芯片制程非常小时(28nm以下),非常明显,mos管由于电压低,电流小,充电受到感抗的影响比40nm大,充电速度慢。芯片想要达到高频率,mos管要加载更高的电压,这样就增加了功耗。漏电也是低制程的一个副作用,也需要提供芯片的功耗才能克服。所以低制程带来的功耗优势就被漏电和二级效应扳回去了很多。
当然,新的工艺、好的工艺可以部分解决上面两个问题,不同工艺用的物理、化学材料不同,工艺流程也不同。高通四核用的是老28nm工艺,目前来看,这个28nm工艺相比40nm工艺优势不大。
然后制程方面,目前听过的最先进的制程是7nm,但这个制程只存在于实验室里,远远没有达到大规模量产的需要。低制程有些困难是难以克服的,学过物理的都知道光的衍射,低制程意味着掩膜透孔会非常小,衍射会非常严重,这样肯定是无法蚀刻硅片的。这个问题也许可以通过使用电子射线或者其他粒子射线来蚀刻硅片解决,但这是那帮孙子去想的问题了。
二、芯片设计考验公司技术水平
说说设计吧,芯片设计分为前端设计和后端设计。前端设计就像做建筑中的画设计图,芯片的逻辑、模块、门电路关系都是前端设计完成的。后端设计则是布局布线,芯片做出来,最终是个实际的东西,那每个mos管摆放什么位置,每一条线怎么连,这个都是后端设计决定的。前端设计没啥好说的,虽然技术含量非常高。
我就说说后端设计吧,有趣一点。5亿个mos管的布局布线,虽然很多用的是IP硬核,别的厂商已经帮忙做好了,但这绝对不是一个轻松的活。拿导线来说,两条导线在一个硅平面上不能交叉,它们可不像我们家里的导线,包了一层塑料。如果把5亿个mos管的导线放在一个平面上,还要让某些连接、某些不连接,还不能
交叉,这绝对是不可能的。
事实上,一个芯片布线,从上到下可能有十几层。每一层都是蜘蛛网一样的布线,如果我们化身成一个1nm的小人,进入芯片的世界走一圈,那绝对会发现那是一个非常宏伟,非常不可思议的世界。后端设计除了要保证线路正确连接,还要使模块占用面积小,功耗小,规避二级效应,要求是很高的。名牌大学毕业搞后端,搞个两年也才刚刚入门。
再说说仿真,芯片在流片之前,谁都不知道它长什么样子,更难以去揣测它设计是否成功、合理,流片成本又非常高,不可能为了验证设计是否成功去流片。这个时候就需要用到仿真,用计算机去模拟电路的运行情况。仿真贯穿芯片设计的始末,有前端仿真、后端仿真、模拟仿真、数字仿真…仿真脱离不了计算机仿真软件,像Sysnopys、Cadence它们是芯片设计、验证软件领域的巨擘,海思每年付给他们的费用我不知道,但起码千万级别。
仿真是一个需要超高性能计算机的任务,海思在IT中心有大量高性能计算机组成云计算资源,但在面对大型仿真时还是很吃力,跑几个小时只能模拟出芯片几秒钟的运行情况。因为要跑仿真,这些计算机一天24小时都在跑。顺便说一下我们部门一个Linux服务器的配置,英特尔4核4GCPU,内存16G。
这个只是一个打杂的服务器,放个数据库,编译几个软件。海思小网的Solaris接入服务器同时有上百人在上面办公。从这点也可以看出,做芯片投入还是非常大的,就光这些软件、硬件成本,每个人每年要花掉公司几十万。
再说说海思目前的水平,我也不想吹牛,确实和美国那些公司比起来有很大差距。毕竟80年代,人家芯片设计、制作都已经非常成熟的时候,我们才有第一台计算机。比如K3V2,它上面很多模块都是别人的,公司花了大笔钱买了版权,这个叫IP核。
IP核分软核和硬核,现在貌似也有软硬结合的核…它是什么东西呢?比如ARM指令授权,它就是软核,它只规定了CPU的指令集,好比建桥,它只告诉你桥应该建多长、多宽、大概长什么样,但是具体细节没有,不告诉你电路在芯片上怎么摆放,怎么连线。软核的好处是给了很大的发挥空间,模仿、抄袭也简单,以后做类似东西可以参考。硬核就是它只告诉你电路在芯片上具体长什么样子,把它摆上去用就行了。硬核的好处是它一般都是经过其它芯片验证的,很容易了解它的具体性能。但你几乎不可能修改它,也很难了解它的实现细节,毕竟有几千万个mos管,人怎么分析。
海思自主IP核不多,主要集中在基带方面和数字电视机顶盒方面,这两块还是比较牛的,海思机顶盒芯片占世界份额90%以上(听老大说)。像K3V2大部分还是在搭积木,搭个USB核,搭一个音频解码核…但客观地说,现在芯片设计分工越来越细,每个公司只是完成其中一小部分,就算是高通,也用了很多其他公司的IP核。
一个公司想把所有活都干了,那绝对是不可能的,就算做到了,它的芯片也不会有竞争力。其实玩搭积木也是很有技术含量的,海思肯定是国内玩得最好的公司。目前公司的一个目标也是把越来越多的模块自主化,但是需要时间。
先从最底层芯片说起,开头说了mos管,现在说说与非门。上面说了mos管是芯片的最小单位,但这是对于芯片制造厂而言的。芯片设计时不会直接画mos管,在数字电路中,使用的最小单位是门电路,与非门就是用得最广泛的一种。一个与非门大概要4个mos管组成,与非门大家应该都非常熟悉。如下图:
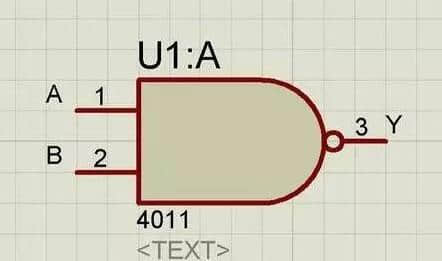
图2
大家都知道,家里的开关有两种状态嘛,打开和关闭。当上图中的开关1和开关2两个开关中只有1个开关打开时,经过与非门处理,开关3就打开了。如果开关1和开关2两个开关都关闭或者两个开关都打开,经过与非门处理,开关3就关闭了。
其实和与非门类似的东西生活中随处可见。比如说有的人家里有一个灯,这个灯在家门口设了一个开关,方便进出家门时开关灯。在床边也设了个开关,方便晚上睡觉时关灯。这个其实就是一个与非门,两个开关控制同一个灯。一个开关打开,灯就亮了,两个开关同时打开或者关闭,灯就灭了。
这样的话,用一个与非门和一个与门就模拟了最简单的一个加法器,最大只能计算1+1。计算机中有几亿个这样的门电路,它们组合起来就能做非常复杂的运算。现在的大部分CPU都是64位的,这种CPU肯定会有64位加法器甚至128位加法器。拿64位加法器来说,它最大可以计算出18446744073709551616 +18446744073709551616。
说到这里,不得不说说芯片频率。K3V2年初时号称1.5G四核,到发布密派时,又改口1.2G,到D1四核,又改成1.4G…可谓坑爹至极,这件事也引发了不少争论。但估计大部分人和我原来一样,只知道争论多少G,不知道这个芯片频率意味着什么。先说说1G是什么概念吧,就是每秒钟10亿(1,000,000,000)次。为什么会有这个东西呢?刚才我说了与非门,开关3是随着开关1和开关2的变化而变化的,对人类来说,开关3的变化速度很快,是瞬间的,但这个变化总是需要一点时间的。开关3可能是另外一个门电路的输入开关,如果变化到一半,它的下一个门电路就接受开关3的输入,可能会产生很严重的问题。
一般来说,一层门电路需要等它的上一层门电路完全变化完毕,输出稳定之后,它才接收上一层的输入,开始变化。这个时候就需要有一个指挥家来指挥这些门电路什么时候开始变化,这个指挥家就是芯片频率,指挥家会定时发出脉冲,1G就是每秒1一次脉冲。门电路等脉冲到来的时候就开始做这个变化。
从上面可以看出,指挥家指挥得越快,芯片运算速度越快。但要说明一点,两倍的频率并不代表两倍的性能。因为CPU和内存、外设频率不同步,它们之间的频率相差越多,CPU空转的次数越多。另外再说一点,门电路变化的过程其实就是mos充电放电的过程,mos管充电放电越快,芯片的频率可以做到越高,而二级效应会减慢mos充电放电的速度。如果mos管想要充电放电快一点,要提高mos管电压,这样就提高了芯片的功耗。
大家对海思比较好奇的,可能都有这么几点疑问:
海思用了ARM的IP核,是不是闭着眼睛就能把K3V2(海思4核A9架构处理器)整出来?
ARM核究竟是怎么回事?
开发K3V2的团队实力如何,在海思地位怎么样?
海思究竟有没有竞争力,核心技术在哪里,和国外比相差多少?
先说说ARM的IP核吧,ARM授权包括指令集和CPU核心架构。据我了解,除了高通外,其它芯片厂商都使用了ARM的CPU核心架构,也就是经常可以听到的A9A15。高通比较高端,CPU核心架构自己搞,如果搞得比A9
A15好的话确实可以提高CPU性能,但由于ARM收取高昂的核心架构修改费用,所以要付更多的钱给ARM。指令集是CPU与上层的编译器、操作系统和应用程序的接口,使用ARM指令集意味着你做的CPU可以兼容安卓系统、安装应用、C编译器。
如果哪个公司自己整一套全新的指令集,那它做出来的CPU一点用处没有,既没有操作系统也没用应用。此前联想出了个K800,用的是英特尔Atom CPU,这款CPU非常特别,使用X86指令集,结果是一出悲剧,很多游戏兼容不了。不过英特尔还得感谢谷歌,否则这个CPU连安卓都兼容不了。目前来看,CPU不用ARM指令集很难玩转,而且随着越来越多应用只支持ARM,ARM的地位会越来越巩固,就像电脑CPU,如果不用X86指令集,连Windows都很难安装,这是一个垄断的帝国。
下面说说CPU核心架构,说之前不得不先谈谈PDK。PDK是ProcessDesign Kit
工艺设计包,它和晶圆厂的制作工艺紧密相关。PDK是什么呢,它描述了一个具体工艺基本元器件的电器特性。比如台积电28nm工艺和40nm工艺做出来的mos管电器特性肯定不一样。28nm工艺和40nm工艺做出来的mos管额定电流范围、电压范围肯定不同,在相同外界输入下,输出曲线也肯定不一样。芯片公司如果没有PDK,根本不知道设计出来的电路性能如何,也没办法跑仿真。简单一点说,你拿40nmPDK设计电路,用28nm工艺生产,生产出来的芯片绝对一点用处没有。所以说芯片设计非常苦逼,搞编程的,代码可以重用,搞芯片设计的,如果换了生产工艺,很多东西得要从头再来。
ARM给华为的CPU核心架构只是FPGA代码,它不是工艺相关的,数字前端设计的工作会少不少,但后端设计有大量的工作要做。但ARM提供的仅仅是一个计算核心,外围一个都没有。外围包括一些什么呢?比如USB IP核,没有这个,手机就没有USB功能;比如GPU,这个不用我多说吧;比如音频IP核,杜比音效就是这么来的;比如视频解码IP核,没有这个,看视频只能软解;还有CPU功耗控制IP核,K3V2功耗低,说明海思这一块做得不错。这些外围的IP核海思很多都是外购的,海思也自主了一部分。所以说看CPU真心不能只看频率,外围IP有好有坏,有些比较高端的IP核授权费用非常高。即使买了很多IP核,但芯片也绝不是闭着眼睛就能整出来的。
顺便说一下,高通芯片外围的IP核很多也是外购的。再说说开发K3V2的海思图灵团队,这个团队的前身是海思平台的数字什么开发部,具体叫什么我忘了,做K3V2之前,也没什么名声。这个团队的技术实力和海思其它开发部的技术实力差不多,因为做K3V2的时候图灵也没有说去别的部门抓厉害的壮丁进去。另外,K3V2完全不能说是海思做的最有技术含量的产品。海思成立七、八年了,做K3V2之前核心技术都在路由器芯片和安防芯片那块。
大家可以去百度一下华为最新的高性能路由器,吞吐量是思科高性能路由器的好几倍,至少领先思科一年。这是怎么做到的呢?因为那些路由器用的是海思专门定制的芯片,这些芯片也是ARM架构的,只是外围IP核变成了处理网络数据的IP核,这些IP核都是有自主知识产权的。把程序写进芯片是目前的一个趋势,典型的例子就是原来播放rmvb都是用播放器软解,软解的时候CPU占用率非常高,稍微清晰一点的容易卡,而现在的CPU或显卡基本都有硬解rmvb的的功能。
把程序写进芯片可以让程序跑得更快,所以华为的路由器在性能上可以超过思科。
所以说海思绝对不是第一次做ARM,能做出四核K3V2也是有原因的,另外八核、十六核目前都在研发过程中。海思在做手机芯片时和国外厂商比,几乎没有任何优势,因为除了K3,原来基本没有做过手机芯片,IP核自主化程度还比较低,优势还得靠积累,这个要慢慢来。另外,海思也有自己的核心技术,其它厂商来做路由芯片,不见得能比海思做得好。
PS:
最近加班得比较晚,九点半回来,洗个澡、拖个地、洗个衣服再墨迹一下就快十点半了。现在有点累了。随便说说工作吧,我想这也是大家非常好奇的一方面,华为工作不是人干的、压榨员工、疯狂加班等传闻在网上早已喜闻乐见。我去之前也有点提心吊胆。现在在公司上班了快三个月,感觉工作压力确实不小,但没有网上说的那么恐怖。平时一般早上八点刷卡,晚上八点多闪人,除去中午下午吃饭时间,每天工作九到十个小时。工作时间一般精神都比较紧张,确实会比很多公司累一点。但这件事怎么看呢?我觉得月薪两万的人和月薪一万的人最大差别就是,月薪两万的创造的价值起码是月薪一万的两倍,有的人挣的多,但付出的肯定也多。美研所有个大牛,我们部门最怕跟他打交道。那家伙提的要求特别多,经常把我们部门的人整死。他年薪50万美元以上,大家羡慕吧。但是我发现他经常下午一两点的时候还在上班,换成美国时间就是凌晨一两点。而且我听说他打算在硅谷买别墅,要500万美元。
最新电子行业资讯、教程以及开发板样片申请,请关注“云汉电子社区”官方微信公众号ickeybbs